-- CONCAT(), CONCAT_WS()
# CONCAT() 함수
SELECT CONCAT('2024', '05', '20');
# CONCAT_WS() 함수
SELECT CONCAT_WS('/', '2024', '05', '20');
CONCAT() 함수CONCAT_WS() 함
<ex1>
-- usertbl 테이블에서 아이디, 이름, 전화번호를 조회
SELECT userID AS "아이디",
NAME AS "이름",
CONCAT( mobile1, mobile2) AS 전화번호
FROM usertbl;
mobile1 과 mobile2를 CONCAT() 함수를 사용하여 이어줌
<ex2>
-- employee 테이블에서 급여 조회
SELECT CONCAT(emp_name, '님의 급여는 ', salary, '입니다.') AS "급여"
FROM employee;
CONCAT() 함수를 통해 조회결과를 문장으로 출력
-- ELT(), FIELD(), FIND_IN_SET(), INSTR(), LOCATE() 함수
# ELT() : 위치번째에 해당하는 문자열을 반환
# 2가 입력되었기 때문에 2에 해당하는 '둘'을 반환
SELECT ELT(2, '하나', '둘', '셋');
# FIELD() : 찾을 문자열의 위치를 찾아서 반환
# '둘' 에 해당하는 문자열이 2번째에 있기 때문에 2를 반환
SELECT FIELD('둘', '하나', '둘', '셋');
# FIND_IN_SET() : 찾을 문자얼의 위치를 찾아서 반환
# 하나의 문자열을 ,(콤마)로 구분하여 찾음
# '둘' 에 해당하는 문자열이 ,(콤마)를 기준으로 2번째에 있기 때문에
# 2 를 반환
SELECT FIND_IN_SET('둘', '하나,둘,셋');
# INSTR() : 기준 문자열에서 부분 문자열을 찾아서 그 시작 위치를 반환
# '둘'이 시작위치가 3번째이기 때문에 3을 반환
SELECT INSTR('하나둘셋', '둘');
# LOCATE() : INSTR()과 순서만 다르고 결과가 동일
# '둘'이 시작위치가 3번째이기 때문에 3을 반환
SELECT LOCATE('둘', '하나둘셋');
ELT() 함수 결과FIELD() 함수 결과FIND_IN_SET() 함수 결과INSTR() 함수 결과LOCATE() 함수 결과
<ex1>
-- employee 테이블에서 이메일의 @ 위치값 출력
SELECT email,
INSTR(email, '@')
FROM employee;
@ 문자의 위치를 찾아 위치값 출력
-- INSERT() 함수
# INSERT('기준 문자열', 삽입 시작 위치, 삭제될 문자 개수, '삽입할 문자')
#1 : 문자 4개 삭제
SELECT INSERT('ABCEDFGHI', 3, 4, '@@@@');
#2 : 문자 2개 삭제
SELECT INSERT('ABCEDFGHI', 3, 2, '@@@@');
#1#2
<ex1>
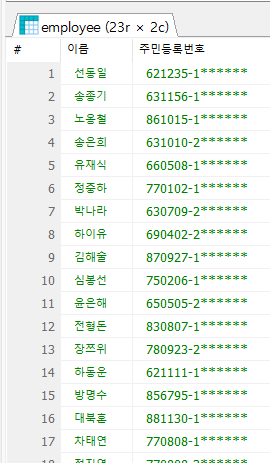
-- employee 테이블에서 사원명, 주민등록번호 조회
SELECT emp_name AS "이름",
INSERT(emp_no, 9, 6, '******') AS "주민등록번호"
FROM employee;
주민등록번호를 앞자리 6 자리와 성별을 제외하고 가려서 출력
-- LEFT(), RIGHT() 함수
# LEFT() : 기준문자열를 왼쪽에서 3개 잘라내어 출력
SELECT LEFT('ABCEDFGHI', 3);
# RIGHT() : 기준문자열를 오른쪽에서 3개 잘라내어 출력
SELECT RIGHT('ABCEDFGHI', 3);
LEFT() 함수 결과RIGHT() 함수 결과
<ex1>
-- employee 테이블에서 사원명, email의 ID만을 출력
SELECT emp_name,
LEFT(email, INSTR(email, '@')-1) AS 'ID'
FROM employee;
INSTR() 함수로 @ 기호의 위치값을 얻어 LEFT() 함수를 통해 ID만을 출력
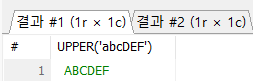
-- UPPER(), LOWER() 함수
# UPPER() : 소문자를 모두 대문자를 변환
SELECT UPPER('abcDEF');
# LOWER() : 대문자를 모두 소문자를 변환
SELECT LOWER('abcDEF');
UPPER() 함수 결과LOWER() 함수 결과
-- LPAD(), RPAD() 함수
# LPAD() : 왼쪽에 남은 문자열 수 넣음
# 문자열을 넣어주지 않으면 공백
SELECT LPAD('HELLO', 10), LPAD('HELLO', 10, '#');
# RPAD() : 오른쪽에 남은 문자열 수 넣음
# 문자열을 넣어주지 않으면 공백
SELECT RPAD('HELLO', 10), RPAD('HELLO', 10, '#');
LPAD() 함수 결RPAD() 함수 결과
<ex1>
-- employee 테이블에서 사원명, 주민등록번호 출력
SELECT emp_name,
RPAD(LEFT(emp_no, 8), 14, '*') AS "주민등록번호"
FROM employee;
LPAD()와 RPAD()를 중첩하여 사용
-- LTRIM(), RTRIM(), TRIM() 함수 사용
# LTRIM(): 왼쪽 공백만 제거
SELECT LTRIM(' HELLO ');
# RTRIM(): 오른쪽 공백만 제거
SELECT RTRIM(' HELLO ');
# TRIM(): 양쪽 공백만 제거
SELECT TRIM(' HELLO ');
LTRIM() 함수 결과RTRIM() 함수 결과TRIM() 함수 결과
-- TRIM(방향 자를 문자열 FROM 문자열)
#1
# 양쪽 공백을 모두 지움
SELECT TRIM(BOTH ' ' FROM ' HELLO ');
#2
# 양쪽 'Z'문자를 모두 지움
SELECT TRIM(BOTH 'Z' FROM 'ZZZZZHELLOZZZZZ');
#3
# 중간에 삽입된 'Z'는 지워지지 않음
SELECT TRIM(BOTH 'Z' FROM 'ZZZZZHEZLLOZZZZZ');
#4
# 왼쪽에 삽입된 'Z'만 지움
SELECT TRIM(LEADING 'Z' FROM 'ZZZZZHEZLLOZZZZZ');
#5
# 오른쪽에 삽입된 'Z'만 지움
SELECT TRIM(TRAILING 'Z' FROM 'ZZZZZHEZLLOZZZZZ');
<ex1>
-- employee 테이블에서 이름, 아이디, 성별 조회
SELECT emp_name,
SUBSTRING(email, 1, INSTR(email, '@')-1) AS '아이디',
IF(SUBSTRING(emp_no, 8, 1) = 1, '남자', '여자') AS '성별'
FROM employee;
SUBSTRING() 함수를 통해 ID 출력, 주민등록번호로 성별 출력
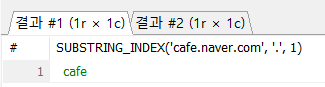
-- SUBSTRING_INDEX() 함수
#1
# 양수 : 왼쪽에서 부터 첫번째 구분자를 찾고 오른쪽 부분을 삭제
SELECT SUBSTRING_INDEX('cafe.naver.com', '.', 1);
#2
# 음수 : 오른쪽에서 부터 첫번째 구분자를 찾고 왼쪽 부분을 삭제
SELECT SUBSTRING_INDEX('cafe.naver.com', '.', -1);
#1#2
<ex1>
-- employee 테이블에서 아이디 조회
SELECT emp_name AS '사원명',
SUBSTRING_INDEX(email, '@', 1) AS '아이디'
FROM employee;
SUBSTRING_INDEX() 함수를 통해 아이디를 조회
4. 수학 함수
-- ABS() 함수: 절대값 출력 함수
SELECT ABS(100), ABS(-100),
ABS(10.9), ABS(-10.9);
ABS() 함수 결과
-- CEILING(), FLOOR(), ROUND(), TRUNCATE() 함수
# CEILING() : 올림 함수
SELECT CEILING(4.3);
# FLOOR() : 내림 함수
SELECT FLOOR(4.7);
# ROUND(x) : ROUND(X, 0)과 동일
SELECT ROUND(4.355), ROUND(4.355, 0);
# ROUND(x, D) : 소수점 D자리까지 반올림
# D 양수 : 소수점 기준
# D 음수 : 자연수 기준
SELECT ROUND(4.355, 2), ROUND(14.355, -1);
# TRUNCATE() : 소수점 기준으로 정수 위치까지 구하고 나머지를 삭제
SELECT TRUNCATE(123.456, 0), TRUNCATE(123.456, 1);
CEILING() 함수 결FLOOR() 함수 결과ROUND(X) 함수 결과ROUND(X, D) 함수결과TRUNCATE()함수 결과
-- MOD() 함수
# MOD(숫자1, 숫자2) : 나머지 함수
# 숫자1을 숫자2로 나눈 나머지값을 반환
SELECT MOD(157, 10) , 157 % 10, 157 MOD 10;
3개의 결과값이 모두 동일
-- RAND() 함수
#1
# RAND() : 0<=X<=1 범위의 값이 랜덤으로 출력
SELECT RAND(), RAND(), RAND();
#2
# RAND() 함수 범위지정
SELECT RAND() * 100 -- 0.0 ~ 99.99999
FLOOR(RAND() * 100), -- 0 ~99
FLOOR(RAND() * 100) +1 ; -- 1 ~ 100
#1#2
-- POW(), SQRT(), SIGN() 함수
# POW() : 거듭 제곱 함수
SELECT POW(2,3);
# SQRT() : 제곱근 함수
SELECT SQRT(9);
# SIGN() : 양수, 0, 음수 판별하는 함수
SELECT SIGN(100), SIGN(0), SIGN(-100);
#1
# ADDTIME() : 시간을 더하는 함수
SELECT ADDTIME('2024-05-20 09:00:00', '01:10:30'), -- 1시간 10분 30초 더하기
ADDTIME('09:00:00', '02:20:50'); -- 2시간 20분 50초 더하기
#2
# ADDTIME() : 시간을 더하는 함수
SELECT SUBTIME('2024-05-20 09:00:00', '01:10:30'), -- 1시간 10분 30초 빼기
SUBTIME('09:00:00', '02:20:50'); -- 2시간 20분 50초 빼기
#1#2
<ex1>
-- employee테이블에서 사원명, 입사일, 인턴(3개월) 종료일 구하기
SELECT emp_name AS '사원명',
hire_date AS '입사일',
ADDDATE(hire_date, INTERVAL 3 MONTH) AS '인턴 종료일'
FROM employee;
ADDDATE()함수를 통해 인턴종료일 출력
-- CURDATE(), CURTIME(), NOW(), SYSDATE() 함수
SELECT CURDATE(), -- 현재 날짜
CURTIME(), -- 현재 시간
NOW(), -- 현재 날짜와 시간
SYSDATE(); -- 현재 날짜와 시간
CURDATE(), CURTIME(), NOW(), SYSDATE() 함수 결과
#1
-- YEAR(), MONTH(), DAY() 함수 : DATE 타입을 입력 받음
SELECT YEAR(CURDATE()), -- 년을 출력
MONTH(CURDATE()), -- 월을 출력
DAY(CURDATE()); -- 일을 출력
#2
-- HOUR(), MINUTE(), SECOND() : TIME 타입을 입력받음
SELECT HOUR(CURTIME()), -- 시간을 출력
MINUTE(CURTIME()), -- 분을 출력
SECOND(CURTIME()); -- 초를 출력
<ex1>
-- employee 테이블에서 직원명, 입사일, 근무 일수 조회
SELECT emp_name AS '직원명',
hire_date AS '입사일' ,
DATEDIFF(CURDATE(), hire_date) AS '근무 일수'
FROM employee;
DATEDIFF()함수로 근무일수 조회
-- DAYOFWEEK(), MONTHNAME(), DAYOFYEAR(), LAST_DAY() 함수 : 날짜 데이터를 입력받음
#1
# DAYOFWEEK() : 날짜의 요일을 반환
# 1: 일요일, 2: 월요일, ..., 7: 토요일
SELECT DAYOFWEEK(CURDATE());
#2
# MONTHNAME() : 날짜의 월의 이름을 반환
SELECT MONTHNAME(CURDATE());
#3
# DAYOFYEAR() : 1년 중 몇 번째 날짜인지를 반환
SELECT DAYOFYEAR(CURDATE());
#4
# LAST_DAY() : 주어진 날짜의 달에 해당하는 마지막 날짜를 반환
SELECT LAST_DAY(CURDATE());
#1#2#3#4
<ex1>
-- employee 테이블에서 직원명, 입사일, 급여일(매달 마지막 날) 조회
SELECT emp_name AS '직원명',
hire_date AS '입사일',
LAST_DAY(CURDATE()) AS '급여일'
FROM employee;
LAST_DAY() 함수를 통해 급여일 지정
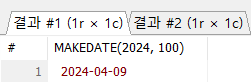
-- MAKEDAY(), MAKETIME() 함수
#1
# MAKEDATE(연도, 정수) : 해당 '연도'에 '정수'만큼 지난 날짜를 반환
SELECT MAKEDATE(2024, 100);
#2 MAKETIME(시, 분, 초) : 입력값에 해당하는 시간을 반환
SELECT MAKETIME(22, 58, 25);
#1#2
-- PERIOD_ADD(), PERIOD_DIFF(), QUARTER(), TIME_TO_SEC() 함수
#1
# PERIOD_ADD(연월, 개월 수) : 연월에서 개월만큼의 개월이 지난 연월을 반환
SELECT PERIOD_ADD(202405, 11);
#2
# PERIOD_DIFF(연월 1, 연월 2) : 연월 1 - 연월 2의 개울 수 반환
SELECT PERIOD_DIFF(202305, 202405);
#3
# QUARTER(날짜) : 날짜가 4분기 중 몇 분기에 해당하는지 반환
SELECT QUARTER(CURDATE());
#4
# TIME_TO_SEC(시간) : 시간을 초 단위로 반환
SELECT TIME_TO_SEC(CURTIME());
#1#2#3#5
6. 시스템 정보 함수
7. 윈도우 함수
7.1. 순위 함수
순위 윈도우 함수에는ROW_NUMBER(),RANK(),DENSE_RANK(),NTILE()등의 함수가 존재
순위 윈도우 함수를 사용하면 데이터를 순서대로 번호 매기거나, 특정 조건에 따라 순위(등수)를 매길 수 있음
-- 윈도우 함수 "순위 함수"
-- ROW_NUMBER() 함수 : 순번을 매김
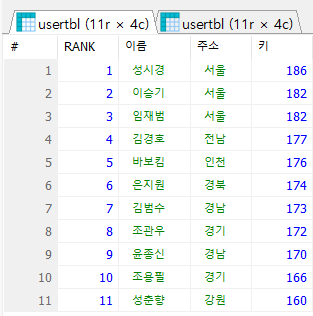
<ex1>
-- usertbl 테이블에서 키가 큰 순으로 순위를 매겨서 순위, 이름, 주소,
-- 키를 조회
# OVER절에 정렬 조건 기입
SELECT ROW_NUMBER() OVER(ORDER BY height DESC, NAME ASC) AS 'RANK',
NAME AS "이름",
addr AS "주소",
height AS "키"
FROM usertbl;
<ex2>
-- usertbl 테이블에서 지역별로 순위를 배겨서 주소 순위, 이름, 키 조회
SELECT addr AS '주소',
ROW_NUMBER() OVER(PARTITION BY addr ORDER BY height DESC, NAME ASC) AS '주소별 순위',
NAME AS '이름',
height AS '키'
FROM usertbl
ORDER BY addr;
<ex1><ex2>
-- 윈도우 함수 "순위 함수"
# RANK() 함수 : 동일한 순위 이후의 등수를 동일한 인원수만큼 건너뛰고 증가
-- usertbl 테이블에서 키가 큰 순으로 순위를 매겨서 순위, 이름, 주소, 키를 조회
SELECT RANK() OVER(ORDER BY height DESC, NAME ASC) AS 'RANK',
NAME AS "이름",
addr AS "주소",
height AS "키"
FROM usertbl;
<ex1>
<ex2>
-- employee 급여가 높은 순서대로 순위 매겨서 순위, 직원명, 급여 조회
SELECT RANK() OVER(ORDER BY salary DESC, emp_name ASC) AS 'RANK',
emp_name AS '직원명',
salary AS '급여'
FROM employee;
<ex2>
-- 윈도우 함수 "순위 함수"
# DENSE_RANK() 함수 : 동일한 순위 이후의 등수를 1 증가
<ex1>
-- usertbl 테이블에서 키가 큰 순으로 순위를 매겨서 순위, 이름, 주소, 키를 조회
SELECT DENSE_RANK() OVER(ORDER BY height DESC, NAME ASC) AS 'RANK',
NAME AS "이름",
addr AS "주소",
height AS "키"
FROM usertbl;
<ex1>
-- 윈도우 함수 "순위 함수"
# NTILE(x) 함수 : 전체 인원을 어떠한 기준 순서로 세운 후에 x개의 그룹으로 분할
<ex1>
# usertbl 테이블에서 키가 순서로 세운 후에 3개의 그룹을 분할
SELECT NTILE(2) OVER(ORDER BY height DESC, NAME ASC) AS 'RANK',
NAME AS "이름",
addr AS "주소",
height AS "키"
FROM usertbl;
<ex1>
7.2. 분석 함수
분석 윈도우 함수에는LEAD(),LAG(),FIRST_VALUE(),LAST_VALUE(),CUME_DIST()등의 함수가 존재
분석 윈도우 함수를 사용하면 현재 행의 이전 행이나 다음 행의 데이터를 참조하거나, 윈도우의 첫 값이나 마지막 값을 가져올 수 있음
-- 윈도우 함수 "분석 함수"
# LEAD(column, n) : n 단위로 다음 등수의 데이터를 가져옴
<ex1>
-- usertbl 테이블에서 키 순서대로 정렬 후 다음 사람과 키 차이를 조회
SELECT NAME AS '직원명',
addr AS '주소',
height AS '키',
height - LEAD(height, 1) OVER(ORDER BY height DESC) AS '다음 등수 키 차이'
FROM usertbl;
<ex1>
-- 윈도우 함수 "분석 함수"
# LAG(column, n) : n 단위로 이전 등수의 데이터를 가져옴
<ex1>
-- usertbl 테이블에서 키 순서대로 정렬 후 다음 사람과 키 차이를 조회
SELECT NAME AS '직원명',
addr AS '주소',
height AS '키',
height - LAG(height, 1) OVER(ORDER BY height DESC) AS '이전 등수 키 차이'
FROM usertbl;
<ex1>
-- 윈도우 함수 "분석 함수"
# FIRT_VALUE(column) : 특정 column의 데이터 중 순위의 가장 첫 번째 값을 가져옴
<ex1>
-- 지역별로 가장 키가 큰 사람과의 키 차이를 조회
SELECT addr AS '주소',
NAME AS '이름',
height AS '키',
height - FIRST_VALUE(height) OVER(PARTITION BY addr ORDER BY height DESC) AS '지역별로 가장 키가 큰 사람과의 키 차이'
FROM usertbl
ORDER BY addr;