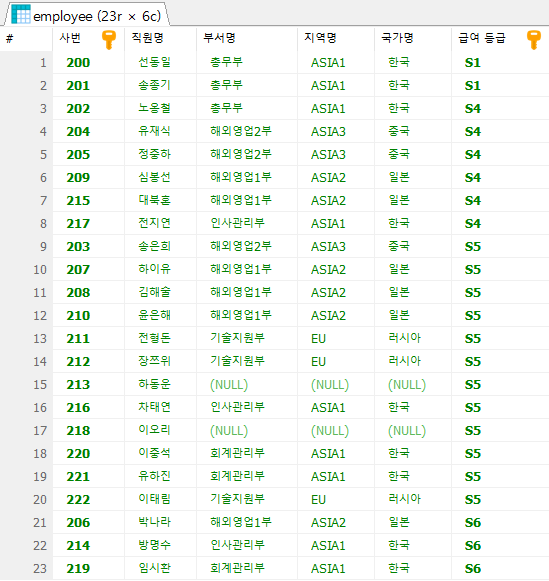
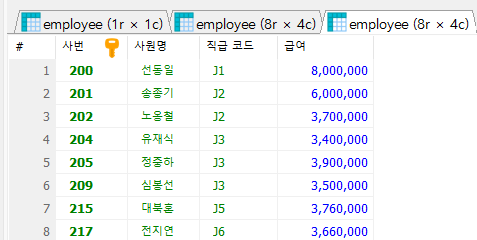
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
d.dept_title AS '부서명',
l.local_name AS '지역명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN location l ON d.location_id = l.local_code
ORDER BY emp_name
;
-- 부서가 있는 사원만
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
d.dept_title AS '부서명',
l.local_name AS '지역명',
n.national_name AS '국가명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN location l ON d.location_id = l.local_code
INNER JOIN national n ON l.national_code = n.national_code
;
-- 부서가 없는 사원도
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
d.dept_title AS '부서명',
l.local_name AS '지역명',
n.national_name AS '국가명'
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
LEFT OUTER JOIN location l ON d.location_id = l.local_code
LEFT OUTER JOIN national n ON l.national_code = n.national_code
;
부서가 존재하는 사원만부서가 존재하지 않는 사원
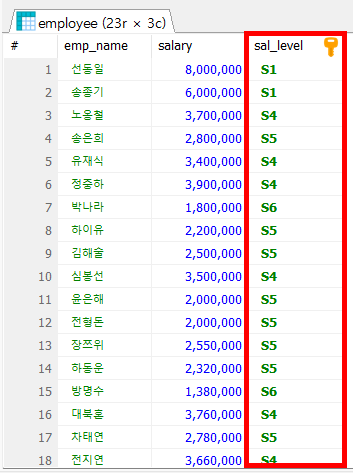
3. 테이블을 다중 JOIN 하여 사번, 직원명, 부서명, 지역명, 국가명, 급여 등급 조회하시오.
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
d.dept_title AS '부서명',
l.local_name AS '지역명',
n.national_name AS '국가명',
g.sal_level AS '급여 등급'
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
LEFT OUTER JOIN location l ON d.location_id = l.local_code
LEFT OUTER JOIN national n ON l.national_code = n.national_code
INNER JOIN sal_grade g ON e.salary BETWEEN g.min_sal AND g.max_sal
;
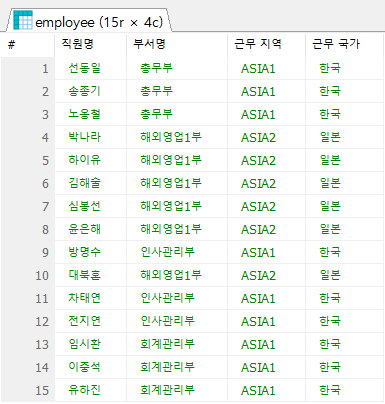
SELECT e.emp_name AS '직원명',
j.job_name AS '직급명',
d.dept_title AS '부서명',
l.local_name AS '근무 지역'
FROM employee e
LEFT OUTER JOIN job j ON e.job_code = j.job_code
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
LEFT OUTER JOIN location l ON d.location_id = l.local_code
;
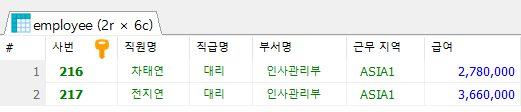
5. 직급이 대리이면서 ASIA 지역에서 근무하는 직원들의 사번, 직원명, 직급명, 부서명, 근무지역, 급여를 조회하시오.
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
j.job_name AS '직급명',
d.dept_title AS '부서명',
l.local_name AS '근무 지역',
e.salary AS '급여'
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN location l ON d.location_id = l.local_code
WHERE l.local_name LIKE 'ASIA%' AND
j.job_name = '대리'
;
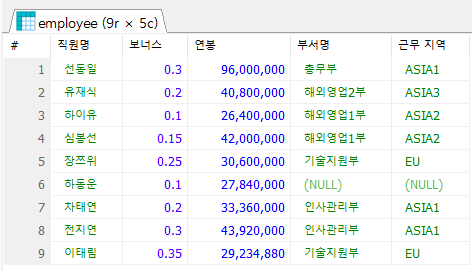
6. 보너스를 받는 직원들의 직원명, 보너스, 연봉, 부서명, 근무지역을 조회하시오. (단, 부서 코드가 없는 사원도 출력될 수 있게 OUTER JOIN 사용)
SELECT e.emp_name AS '직원명',
e.bonus AS '보너스',
e.salary * 12 AS '연봉',
d.dept_title AS '부서명',
l.local_name AS '근무 지역'
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
LEFT OUTER JOIN location l ON d.location_id = l.local_code
WHERE bonus IS NOT NULL
;
7. 한국과 일본에서 근무하는 직원들의 직원명, 부서명, 근무지역, 근무 국가를 조회하시오.
SELECT e.emp_name AS '직원명',
d.dept_title AS '부서명',
l.local_name AS '근무 지역',
n.national_name AS '근무 국가'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN location l ON d.location_id = l.local_code
INNER JOIN national n ON l.national_code = n.national_code
WHERE n.national_name IN ('한국', '일본')
;
다른 JOIN은 같은 지를 비교하지만 NON EQUAL JOIN은 조인 조건에 등호(=)를 사용하지 않는 조인
-- NON EQUAL JOIN 실습
-- 조인 조건에 등호(=)를 사용하지 않는 조인문을 비등가 조인이라고 한다.
-- employee 테이블과 sal_grade 테이블을 비등가 조인하여 직원명, 급여, 급여 등급 조회
-- INNER JOIN이기 때문에 조인 조건을 만족하는 경우가 아니면 출력이 안됨
SELECT e.emp_name,
e.salary,
s.sal_level
FROM employee e
INNER JOIN sal_grade s ON e.salary >= s.min_sal AND e.salary <= s.max_sal
# INNER JOIN sal_grade s ON e.salary between s.min_sal AND s.mas_sal과 결과 동일
;
CREATE [OR REPLACE] VIEW 뷰 이름
AS 서브 쿼리
[WITH CHECK OPTION];
-- VIEW 실습
#1 뷰 생성
CREATE VIEW v_employee
AS SELECT e.emp_id,
e.emp_name,
d.dept_title,
j.job_name,
e.hire_date
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
LEFT OUTER JOIN job j ON e.job_code = j.job_code;
#1
-- 사원의 사번, 직원명, 성별, 급여를 조회할 수 있는 뷰를 생성
#2
# OR REPLACE : 같은 이름의 뷰가 존재한다면 해당 뷰의 내용을 해당 쿼리문으로 덮어씀
# SELECT 쿼리에 함수나, 산술연산이 기술되어 있는 경우 별칭을 지정해야 한다.
CREATE OR REPLACE VIEW v_employee
AS SELECT emp_id,
emp_name,
if(SUBSTRING(emp_no, 8, 1)='1', '남자', '여자') AS gender,
salary
FROM employee;
SELECT * FROM v_employee;
3. 뷰의 수정
뷰를 수정할 때는 ALTER VIEW 구문을 사용
ALTER VIEW 뷰 이름 AS 서브 쿼리;
-- 뷰 수정
ALTER VIEW v_userbuy
AS SELECT u.userid,
u.NAME,
b.prodName,
u.addr,
CONCAT(u.mobile1, u.mobile2) AS 'mobile'
FROM usertbl u
INNER JOIN buytbl b ON u.userId = b.userID
;
4. 뷰의 삭제
뷰를 삭제할 때는 DROP VIEW구문을 사용
DROP VIEW 뷰 이름;
5. 뷰의 DML 작업
DML 작업이 가능한 경우
-- 뷰를 이용해서 DML(INSERT, UPDATE, DELETE) 사용
#1 v_job 생성
CREATE OR REPLACE VIEW v_job
AS SELECT *
FROM job
;
#1 v_job 뷰 생
#2 VIEW INSERT (job_code = 'J8', job_name = '알바' 데이터 삽입)
INSERT INTO v_job VALUES('J8', '알바');
SELECT * FROM v_job;
SELECT * FROM job
#2 view에 데이터가 삽입됨
#3 원본 테이블에도 데이터가 삽입
#3 VIEW UPDATE (J8 직급명을 인턴으로 변경)
UPDATE v_job
SET job_name = '인턴'
WHERE job_code = 'J8'
;
#3 데이터의 내용이 변경됨#3 원본 테이블 값도 함께 변경
#4 VIEW DELETE (J8 직급명인 데이터를 삭제)
DELETE
FROM v_job
WHERE job_code = 'J8'
;
#4 데이터가 삭제됨#4 원본 테이블의 데이터도 함께 삭제
DML 조작이 불가능한 경우
1. 뷰 정의에 포함되지 않는 열을 조작하는 경우
#1 v_job 뷰 생성
CREATE OR REPLACE VIEW v_job
AS SELECT job_code
FROM job
;
-- 1.INSERT
#1 VIEW에 정의된 열에 값을 삽입하는 것은 불가
# 제약 조건에 위배되는 값을 넣어도 에러 발생
INSERT INTO v_job VALUES('J8', '인턴');
#2 데이터 삽입이 가능
INSERT INTO v_job VALUES('J8');
-- 2.UPDATE
#1 v_job 뷰는 job_code만 접근할 수 있기 때문에 에러발생
UPDATE v_job
SET job_name = '인턴'
WHERE job_code = 'J8'
;
#2 데이터 수정이 가능
UPDATE v_job
SET job_code = 'J0'
WHERE job_code = 'J8'
;
-- 3.DELETE
#1 v_job 뷰는 job_code만 접근할 수 있기 때문에 에러발생
DELETE
FROM v_job
WHERE job_name IS NULL
;
#2
DELETE
FROM v_job
WHERE job_code = 'J0'
;
2. 산술 표현법으로 정의 된 경우
#1 v_emp_salary 뷰 생성
-- 사원의 연봉 정보를 조회하는 뷰
CREATE VIEW v_emp_salary
AS SELECT emp_id,
emp_name,
emp_no,
salary * 12 AS 'salary'
FROM employee
;
-- 1.INSERT
#1 산술 연산으로 정의된 컬럼은 데이터 삽입이 불가능
INSERT INTO v_emp_salary
VALUES ('100', '홍길동', '940523-1111111', '30000000');
#2 산술 연산과 무관한 컬럼은 데이터 삽입 가능
INSERT INTO v_emp_salary(emp_id, emp_name, emp_no)
VALUES ('100', '홍길동', '940523-1111111');
-- 2.UPDATE
#1. 산술 연산으로 정의된 열은 데이터 변경 불가능
UPDATE v_emp_salary
SET salary = 30000000
WHERE emp_id = '100'
;
#2. 산술 연산과 무관한 열은 데이터 변경 가능
UPDATE v_emp_salary
SET emp_name = '고길동'
WHERE emp_id = '100'
;
-- 3.DELETE
# 가상으로 설정된 값을 입력하고 변경하는 것이 아닌
# 조회해서 삭제하는 것은 가능
DELETE
FROM v_emp_salary
WHERE salary = 36000000;
3. 그룹 함수나 GROUP BY 절을 포함한 경우(DISTINCT도 동일)
#1 v_emp_salary 뷰 생성
CREATE OR REPLACE VIEW v_emp_salary
AS SELECT dept_code,
FLOOR(SUM(salary)) AS 'sum',
floor(AVG(salary)) AS 'avg'
FROM employee
GROUP BY dept_code
;
-- 1.INSERT
#1 그룹 함수로 생성된 열은 가상의 열이기때문에 삽입이 불가능
INSERT INTO v_emp_salary VALUES('D7', 8000000, 4000000);
#2 GROUP BY로 생성된 테이블의 dept_code열에는 삽입이 불가능
INSERT INTO v_emp_salary(dept_code) VALUES('D7');
-- 2.UPDATE
#1 그룹 함수로 생성된 열은 가상의 열이기때문에 수정이 불가능
UPDATE v_emp_salary
SET SUM = 6000000
WHERE dept_code = 'D2'
;
#2 GROUP BY로 생성된 테이블의 dept_code 열은 수정이 불가능
# 원본 테이블의 해당 dept_code인 열이 모두 수정 되기 때문
UPDATE v_emp_salary
SET dept_code = 'D7'
WHERE dept_code = 'D2'
;
-- 3.DELETE
#1 GROUP BY로 생성된 테이블의 dept_code 열은 삭제가 불가능
# 원본 테이블의 해당 dept_code인 열이 모두 삭제 되기 때문
DELETE
FROM v_emp_salary
WHERE dept_code = 'D2'
;
-- 2.UPDATE
#1 실행 가능
UPDATE v_emp_dept
SET dept_title = '총무1팀'
WHERE emp_id = '200'
;
#2 실행 가능
UPDATE v_emp_dept
SET emp_name = '서동일'
WHERE emp_id = '200'
;
-- 3.DELETE
#1 오류 발생
DELETE
FROM v_emp_dept
WHERE emp_id = '202'
;
SELECT u.NAME AS '이름',
u.addr AS '주소',
CONCAT(u.mobile1, u.mobile2) AS '연락처',
b.prodName AS '주문 상품'
FROM usertbl u
INNER JOIN buytbl b ON u.userID = b.userID
WHERE u.userID = 'JYP';
Q2. employee 테이블과 department 테이블을 조인하여 보너스를 받는 사원들의 사번, 직원명, 보너스, 부서명을 조회하시오.
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
e.bonus AS '보너스',
d.dept_title AS '부서명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
WHERE e.bonus IS NOT NULL;
Q3. employee 테이블과 department 테이블을 조인하여 인사관리부가 아닌 사원들의 직원명, 부서명, 급여를 조회하시오.
SELECT e.emp_name AS '직원명',
d.dept_title AS '부서명',
e.salary AS '급여'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
WHERE d.dept_title != '인사관리부';
# ['employee' JOIN 'department'] JOIN 'job'
# 순서가 잘못되면 JOIN이 안될 수도 있음
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
d.dept_title AS '부서명',
j.job_name AS '직급명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN job j ON e.job_code = j.job_code;
Q5. 70년대생 이면서 여자이고, 성이 전 씨인 직원들의 직원명, 주민번호, 부서명, 직급명을 조회하시요.
SELECT e.emp_name AS '직원명',
e.emp_no AS '주민번호',
d.dept_title AS '부서명',
j.job_name AS '직급명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN job j ON e.job_code = j.job_code
WHERE e.emp_no LIKE '7%'
AND SUBSTRING(e.emp_no, 8, 1) = 2
AND e.emp_name LIKE '전%'
;
Q6. 각 부서별 평균 급여를 조회하여 부서명, 평균 급여를 조회 단 부서 배치가 안된 사원들의 평균도 같이 나오게끔 조회하시오.
SELECT IFNULL(d.dept_title, '부서없음')AS '부서명',
FLOOR(AVG(e.salary)) AS '평균 급여'
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_ID
GROUP BY d.dept_title
ORDER BY d.dept_title
;
SELECT d.dept_title AS '부서명',
SUM(e.salary) AS '급여의 합'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_ID
GROUP BY d.dept_title
HAVING SUM(e.salary) >= 10000000
ORDER BY SUM(e.salary) DESC
;
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
j.job_name AS '직급명'
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE e.emp_name LIKE '%형%';
SELECT e.emp_name AS '직원명',
j.job_name AS '직급명',
e.dept_code AS '부서코드',
d.dept_title AS '부서명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
INNER JOIN job j ON e.job_code = j.job_code
WHERE d.dept_title LIKE '해외영업%'
ORDER BY d.dept_title
;
Q10. 각 부서별 최소 급여를 받는 사원들의 사번, 이름, 부서코드, 급여를 조회하시오.
SELECT emp_id AS '사번',
emp_name AS '사원명',
IFNULL(dept_code, '부서없음') AS '부서코드',
salary AS '급여'
FROM employee
WHERE (salary, IFNULL(dept_code, '부서없음')) IN (
SELECT MIN(salary), IFNULL(dept_code, '부서없음')
FROM employee
GROUP BY dept_code
)
ORDER BY dept_code
;
Q11. 각 직급별로 최소 급여를 받는 사원들의 사번, 이름, 직급코드, 급여 조회하시오.
SELECT emp_id AS '사번',
emp_name AS '사원명',
job_code AS '직급코드',
salary AS '급여'
FROM employee
WHERE (salary, job_code) IN (
SELECT MIN(salary), job_code
FROM employee
GROUP BY job_code
)
ORDER BY job_code
;
조인 중에서 가장 많이 사용되는 조인으로 일반적으로 조인이라고 이야기하는 것이 이 내부 조인(INNER JOIN)을 지칭하는 것
FROM 절 다음에 INNER JOIN구문을 통해 조인에 사용할 테이블을 기술하고 ON 절에 조인 조건을 작성
SELECT *
FROM employees e
INNER JOIN departments d ON e.dept_no = d.dept_no;
<ex1>
-- INNER JOIN 실습
-- 각 사원들의 사번, 직원명, 부서코드, 부서명을 조회
# e와 d는 각각 employee 테이블과 department 테이블의 별칭
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
dept_title AS '부서명'
FROM employee e
INNER JOIN department d ON dept_code = d.dept_id;
<ex2-1>
-- 각 사원들의 사번, 직원명, 직급 코드, 직급명을 조회
# job_code가 컬럼 이름이 두개의 테이블에서 모두 동일하기 때문에
# 에러가 발생
SELECT emp_id AS '사번',
emp_name AS '직원명',
job_code AS '직급 코드',
job_name AS '직급명'
FROM employee
INNER JOIN job ON job_code = job_code;
에러 발생
<ex2-2>
-- 각 사원들의 사번, 직원명, 직급 코드, 직급명을 조회
-- 방법 1) 테이블명 언급
SELECT employee.emp_id AS '사번',
employee.emp_name AS '직원명',
employee.job_code AS '직급 코드',
job.job_name AS '직급명'
FROM employee
INNER JOIN job ON employee.job_code = job.job_code;
방법 1
<ex2-3>
-- 각 사원들의 사번, 직원명, 직급 코드, 직급명을 조회
-- 방법 2) 별칭 사용
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
e.job_code AS '직급 코드',
j.job_name AS '직급명'
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code;
방법 2
<ex2-4>
-- 각 사원들의 사번, 직원명, 직급 코드, 직급명을 조회
-- NATURAL JOIN : 동일한 컬럼명을 가지고 알아서 JOIN
-- 방법3) NATURAL JOIN > 하지만 잘 사용하지 않음
SELECT emp_id,
emp_name,
job_code,
job_name
FROM employee
NATURAL JOIN job;
<ex2-4>
<ex3>
-- join 조건을 where 절에서도 사용이 가능
-- 하지만 join 조건은 INNER JOIN에, 검색 조건은 WHERE절에 기입하는걸 추천
SELECT e.emp_id,
e.emp_name,
j.*
FROM employee e
INNER JOIN job j
WHERE e.job_code = j.job_code;
#1
SELECT *
FROM employee e;
#2
SELECT *
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id;
#1#2
- #1의 실행결과는 23행이 조회되고 #2는 21행이 조회된다. 이유는 JOIN 조건에서 조건값이 NULL값인 행들은 JOIN이 되지 않기때문이다.
3. 외부 조인(OUTER JOIN)
외부 조인(OUTER JOIN)은 조인의 조건에 만족되지 않는 행까지도 조회하기 위해서 사용되는 조인
LEFT OUTER JOIN은 왼쪽 테이블의 데이터는 모두 조회하려고 할 때 사용
SELECT *
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_no = d.dept_no;
#1
-- OUTER JOIN과 비교할 INNER JOIN 구문
-- 부서가 지정되지 않은 사원 2명에 대한 정보가 조회되지 않음
-- 부서가 지정되어 있어도 부서에 속해있는 사원이 없으면
-- 부서에 대한 정보가 조회되지 않는다.
SELECT e.emp_name,
d.dept_title,
e.dept_code,
e.salary
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
ORDER BY e.dept_code;
#2 LEFT OUTER JOIN
-- employee테이블을 기준으로 조인
-- JOIN 조건에 부합되지 않아도 employee테이블은 모두 나옴
-- 부서 코드가 없던 사원의 정보가 출력된다.
SELECT e.emp_name,
d.dept_title,
e.dept_code,
e.salary
FROM employee e
LEFT OUTER JOIN department d ON e.dept_code = d.dept_id
ORDER BY e.dept_code;
#1 부서가 지정되지 않은 사원의 정보는 조회되지 않음#2 부서가 지정되지 않은 사원의 정보도 조회가 가능
RIGHT OUTER JOIN은 오른쪽 테이블의 데이터는 모두 조회하려고 할 때 사용
SELECT *
FROM employees e
RIGHT OUTER JOIN departments d ON e.dept_no = d.dept_no;
#1
-- OUTER JOIN과 비교할 INNER JOIN 구문
-- 부서가 지정되지 않은 사원 2명에 대한 정보가 조회되지 않음
-- 부서가 지정되어 있어도 부서에 속해있는 사원이 없으면
-- 부서에 대한 정보가 조회되지 않는다.
SELECT e.emp_name,
d.dept_title,
e.dept_code,
e.salary
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
ORDER BY e.dept_code;
#2 RIGHT OUTER JOIN
-- 부서에 속해있는 사원이 없어도 부서에 대한 정보가 출력된다.
SELECT e.emp_name,
d.dept_title,
e.dept_code,
e.salary
FROM employee e
RIGHT OUTER JOIN department d ON e.dept_code = d.dept_id
ORDER BY e.dept_code;
#1 부서가 지정되지 않은 사원의 정보는 조회되지 않음#2 부서에 속해있는 사원이 없어도 부서에 대한 정보가 출력
4. 상호 조인(CROSS JOIN)
상호 조인(CROSS JOIN)은 한쪽 테이블의 모든 행들과 다른 쪽 테이블의 모든 행을 조인
거의 사용되지 않음
SELECT *
FROM employees e
CROSS JOIN departments d;
-- CROSS JOIN 실습
# 3개의 행을 가지고 있는 테이블A와
# 3개의 행을 가지고 있는 테이블B를 CROSS JOIN을 하면
# 총 9개의 행이 나옴
# 즉, 테이블A 행 개수 * 테이블B 행 개수
# employee 테이블은 23행이고
# department 테이블은 9행이므로
# 207행이 출력
SELECT e.emp_name,
d.dept_title
FROM employee e
CROSS JOIN department d
ORDER BY e.emp_name;
CROSS JOIN 결과 207행이 출
5. 자체 조인(SELF JOIN)
자체 조인(SELF JOIN)은 동일한 테이블을 가지고 조인하여 데이터를 조회
자기 자신과 JOIN
테이블 별칭을 각각 다르게 부여하여 두개의 테이블을 구별하여 JOIN
SELECT *
FROM employees e
INNER JOIN employees M ON e.manager_no = m.emp_no;
<ex1>
-- SELF JOIN
#1
# manager_id = 사수의 emp_id
SELECT *
FROM employee;
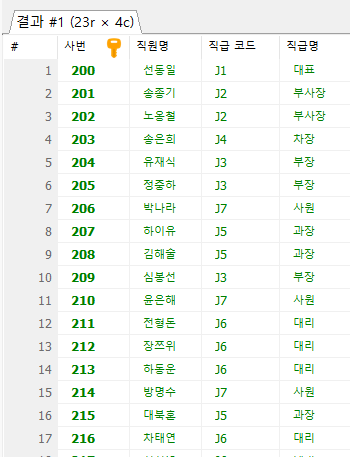
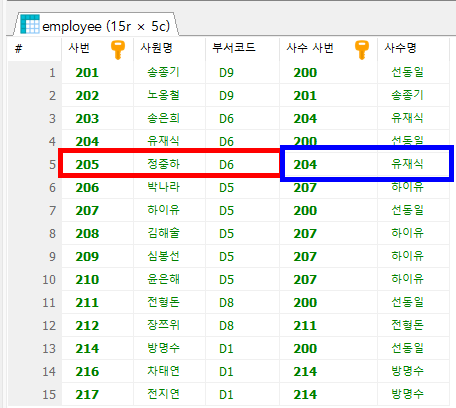
-- employee 테이블을 SELF JOIN하여 사번, 사원 이름, 부서 코드,
-- 사수 사번, 사수 이름 조회
#2
SELECT e.emp_id AS '사번',
e.emp_name AS '사원명',
e.dept_code AS '부서코드',
m.emp_id AS '사수 사번', -- e.manager_id와 동일
m.emp_name AS '사수명'
FROM employee e
INNER JOIN employee m ON e.manager_id = m.emp_id
;
#1 emp_id 와 manager_id 를 조건으로 JOIN할 것임#2 R: 직원정보 B: 사수정보
<ex2>
-- 사수가 없는 사원의 정보도 출력할 수 있도록
-- LEFT OUTER JOIN과 SELF JOIN 함께 사용
SELECT e.emp_id AS '사번',
e.emp_name AS '사원명',
e.dept_code AS '부서코드',
m.emp_id AS '사수 사번',
m.emp_name AS '사수명'
FROM employee e
LEFT OUTER JOIN employee m ON e.manager_id = m.emp_id
;
사수가 없는 사원의 정보도 LEFT OUTER JOIN을 사용하여 조회
6. UNION/UNION ALL 연산자
UNION연산자는 두 쿼리의 결과를 하나로 합치는 연산자
쿼리 A에서 2개의 행, 쿼리 B에서 3개의 행이 조회되면 총 5개의 행을 출력
두개의 쿼리문의 SELECT 절에서 사용한 컬럼의 개수가 동일하지 않으면 오류발생
UNION 연산자는 중복된 열은 제거되고 데이터가 정렬되어 조회
UNION ALL 연산자는 UNION 연산자와 다르게 중복된 열까지 모두 출력
SELECT *
FROM employees
WHERE gender = '남자'
UNION -- 또는 UNION ALL
SELECT *
FROM employees
WHERE salary > 3000000;
#0 UNION 연산자에 사용할 쿼리문
#0-1
-- employee 테이블에서 부서 코드가 D5인 사원들의 사번, 직원명, 부서코드,
-- 급여를 조회
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE dept_code = 'D5'
;
#0-2
-- employee 테이블에서 급여가 300만원 초과인 사원들의 사번, 직원명,
-- 부서 코드, 급여를 조회
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE salary > 3000000
;
# 0-1# 0-2
#1 UNION 연산자
<ex 1>
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE dept_code = 'D5'
UNION
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE salary > 3000000
;
-- WHERE 절로 변경
-- UNION 연산자를 사용하여 조회한 것과 결과 동일
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE dept_code = 'D5' OR salary > 3000000
사번 209, 215인 정보는 두 쿼리문에 모두 동일하게 조회되기 때문에 중복은 제거하고 출
#2 UNION ALL
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE dept_code = 'D5'
UNION
SELECT emp_id AS '사번',
emp_name AS '직원명',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE salary > 3000000
;
#2 UNION ALL은 중복된 값도 제거하지 않고 출력
서브쿼리(SubQuery )
1. 서브쿼리(SubQuery)
하나의 SQL문 안에 포함된 또 다른 SQL 문
-- 서브 쿼리 실습
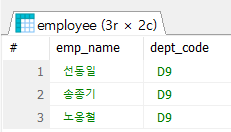
#1. 노옹철 사원과 같은 부서원들을 조회
#1-1 노옹철 사원의 부서를 조회
SELECT emp_name,
dept_code
FROM employee
WHERE emp_name = '노옹철';
#1-2 부서 코드가 노옹철 사원의 부서 코드와 동일한 사원들을 조회
SELECT emp_name,
dept_code
FROM employee
WHERE dept_code = 'D9';
#1-3 위의 2단계를 서브 쿼리를 사용하여 하나의 쿼리문을 ㅗ작성
SELECT emp_name,
dept_code
FROM employee
WHERE dept_code = (
SELECT dept_code
FROM employee
WHERE emp_name = '노옹철'
);
#1-1
#1-2#1-3
#2
-- 전 직원의 평균 급여보다 더 많은 급여를 받고 있는 직원들의 사번,
-- 직원명, 직급 코드, 급여를 조회
#2-1 전 직원의 평균 급여 조회
SELECT FLOOR(AVG(salary))
FROM employee
;
#2-2 평균 급여보다 더 많은 급여를 받고 있는 직원들을 조회
SELECT emp_id AS '사번',
emp_name AS '사원명',
job_code AS '직급 코드',
salary AS '급여'
FROM employee
WHERE salary > 3047662
;
#2-3 위의 2단계를 서브 쿼리를 사용하여 하나의 쿼리문으로 작성
SELECT emp_id AS '사번',
emp_name AS '사원명',
job_code AS '직급 코드',
salary AS '급여'
FROM employee
WHERE salary > (
SELECT FLOOR(AVG(salary))
FROM employee
);
#2-1#2-2#2-3
2. 서브 쿼리 구분
서브 쿼리는 서브 쿼리를 수행한 결과값의 행과 열의 개수에 따라서 분류 가능
단일행 서브쿼리 : 서브 쿼리의 조회 결과 값의 개수가 1개일 경우
#1
-- 노옹철 사원의 급여보다 더 많이 받는 사원의 사번, 직원명,
-- 부서명, 급여 조회
#1-1 노옹철 사원의 급여
SELECT salary
FROM employee
WHERE emp_name = '노옹철'
;
#1-2 노옹철 사원의 급여보다 더 ㅁ낳이 받는 사원을 조회
SELECT e.emp_id AS '사번',
e.emp_name AS '사원명',
d.dept_title AS '부서명',
e.salary AS '급여'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
WHERE salary > 3700000
;
#1-3 서브쿼리를 활용하여 #1-1과 #1-2를 취합
SELECT e.emp_id AS '사번',
e.emp_name AS '사원명',
d.dept_title AS '부서명',
e.salary AS '급여'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
WHERE salary > (
SELECT salary
FROM employee
WHERE emp_name = '노옹철'
)
;
#1-1#1-2#1-3
다중행 서브쿼리 : 서브 쿼리의 조회 결과 값의 개수가 여러 행일 경우
다중행 서브쿼리는 조회 결과값이 여러개이기 때문에 단순비교 연산자를 사용 불가능(에러 발생)
ANY 연산자
ALL 연산자
#1
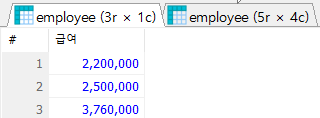
-- 각 부서별 최고 급여를 받는 직원의 이름, 직급 코드, 부서코드, 급여 조회
#1
-- 각 부서별 최고 급여를 받는 직원의 이름, 직급 코드, 부서코드, 급여 조회
#1-1 부서별 최고 급여 조회
SELECT MAX(salary) AS '해당 부서의 최고 급여'
FROM employee
GROUP BY dept_code
;
#1-2 위 급여를 받는 사원들을 조회
SELECT emp_name AS '사원명',
job_code AS '직급코드',
dept_code AS '부서 코드',
salary AS '급여'
FROM employee
WHERE salary IN (2890000, 3660000, 2490000, 3760000, 3900000, 2550000, 8000000)
ORDER BY dept_code
;
#1-3 #1-1과 #1-2를 서브쿼리를 사용하여 취합
SELECT emp_name AS '사원명',
job_code AS '직급코드',
dept_code AS '부서 코드',
salary AS '급여'
FROM employee
WHERE salary IN (
SELECT MAX(salary) AS '해당 부서의 최고 급여'
FROM employee
GROUP BY dept_code
)
ORDER BY dept_code
;
#1-1#1-2#1-3
#2
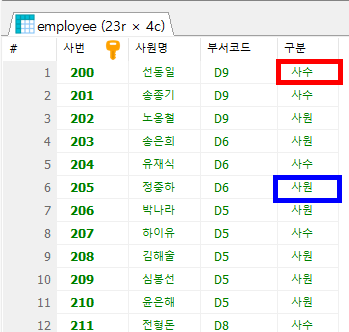
-- 직원에 대해 사번, 이름, 부서코드, 구분(사원/사수) 조회
#2-1 사수에 해당하는 사번을 조회
SELECT DISTINCT manager_id AS '사수번호'
FROM employee
WHERE manager_id IS NOT NULL
;
#2-2 사수/ 사원을 구분하여 조회
SELECT emp_id AS '사번',
emp_name AS '사원명',
dept_code AS '부서코드',
CASE WHEN emp_id IN (200, 201, 204, 207, 211, 214,100) THEN '사수'
ELSE '사원'
END AS '구분'
FROM employee
;
#2-3 SELECT 절에 서브 쿼리를 사용
SELECT emp_id AS '사번',
emp_name AS '사원명',
dept_code AS '부서코드',
CASE WHEN emp_id IN (
SELECT DISTINCT manager_id AS '사수번호'
FROM employee
WHERE manager_id IS NOT NULL
) THEN '사수'
ELSE '사원'
END AS '구분'
FROM employee
;
#2-1#2-2#2-3 #2-2와 결과 동일
ANY 연산자는 서브쿼리의 결과 중 하나라도 조건을 만족하면 TRUE를 반환
#1
-- 대리 직금임에도 과장 직급들의 최소 급여보다
-- 많이 맏는 직원의 사번, 이름, 직급코드, 급여 조회
#1-1 과장 직급들의 급여 조회
SELECT salary AS '급여'
FROM employee
WHERE job_code = 'J5'
;
#1-2 WHERE 절에 ANY를 이용하여 서브 쿼리를 사용
SELECT emp_id AS '사번',
emp_name AS '이름',
job_code AS '직급코드',
salary AS '급여'
FROM employee
WHERE job_code = 'J6' AND
-- AND salary > 2200만 OR salary > 250만 OR salary > 376만 과 동일
salary > ANY (
SELECT salary AS '급여'
FROM employee
WHERE job_code = 'J5'
)
;
#1-1#1-2
ALL 연산자는 서브쿼리의 결과 모두가 조건을 만족하면 TRUE를 반환한다.
= 기호는 논리적 오류가 있으므로 사용이 불가
#1
-- 과장 직급임에도 차장 직급의 최대 급여보다 더 많이 받는ㄴ
-- 직원들의 사번, 이름, 직급, 급여 조회
#1-1 차장 직급들의 급여 조회
SELECT salary
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE j.job_name = '차장'
;
#1-2 WHERE 절에 ANY를 이용하여 서브 쿼리를 사용
SELECT e.emp_id AS '사번',
e.emp_name AS '사원명',
j.job_name AS '직급명',
e.salary AS '급여'
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE j.job_name = '과장'
AND salary > ALL ( -- salary > 280만 AND salary > 155만 AND salary > 249만 AND salary > 248만
SELECT salary
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE j.job_name = '차장'
)
;
#1-1#1-2
다중열 서브쿼리 : 서브 쿼리의 조회 결과 값은 한 행이지만 열의 수가 여러개일 경우
#1
-- 하이유 사원과 같은 부서코드, 직급 코드에 해당하는 사원들을 조회
#1-1 하이유 사원의 부서 코드와 직급 코드 조회
SELECT dept_code AS '부서코드',
job_code AS '직급 코드'
FROM employee
WHERE emp_name = '하이유'
;
#1-2 부서 코드가 D5이면서 직급 코드가 J5인 사람들을 조회
SELECT emp_name AS '사원명',
dept_code AS '부서코드',
job_code AS '직급 코드'
FROM employee
WHERE dept_code = 'D5' AND job_code = 'J5'
;
#1-3 2개의 서브 쿼리를 사용하여 부서 코드가 D5이면서 직급 코드가 J5인 사람들을 조회
SELECT emp_name AS '사원명',
dept_code AS '부서코드',
job_code AS '직급 코드'
FROM employee
WHERE dept_code = (
SELECT dept_code
FROM employee
WHERE emp_name = '하이유'
)
AND job_code = (
SELECT job_code
FROM employee
WHERE emp_name = '하이유'
)
;
#1-4 1개의 서브 쿼리를 사용하여 부서 코드가 D5이면서 직급 코드가 J5인 사람들을 조회
# 쌍 비교 방식 : (,) = (,)형식으로 여러개의 컬럼을 동시에 비교
SELECT emp_name AS '사원명',
dept_code AS '부서코드',
job_code AS '직급 코드'
FROM employee
WHERE (dept_code, job_code) = (
SELECT dept_code AS '부서코드',
job_code AS '직급 코드'
FROM employee
WHERE emp_name = '하이유'
)
;
#1-1#1-2#1-3#1-4
#2
-- 박나라 사원과 직급 코드가 일치하면서 같은 사수를 가지고 있는
-- 사원의 사번, 이름, 직급 코드, 사수 사번 조회
#2-1 박나라 사원의 직급 코드와 사수의 사번을 조회
SELECT job_code AS '직급 코드',
manager_id AS '사수 사번'
FROM employee
WHERE emp_name = '박나라'
;
#2-2 서브쿼리사용하여 작성
SELECT emp_id AS '사번',
emp_name AS '사원명',
job_code AS '직급 코드',
manager_id AS '사수 사번'
FROM employee
WHERE (job_code, manager_id) = (
SELECT job_code,
manager_id
FROM employee
WHERE emp_name = '박나라'
)
;
#2-1#2-2
다중행 다중열 서브쿼리 : 서브 쿼리의 조회 결과값이 여러 행, 여러 열일 경우
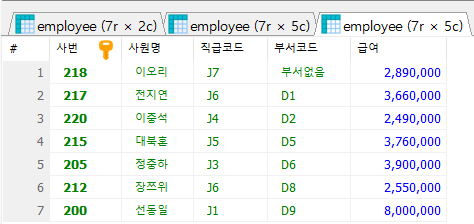
#1
-- 각 부서별 최고 급여를 받는 직원의 사번, 이름, 직급 코드, 부서코드, 급여 조회
#1-1 부서별 최고 급여 조회
SELECT dept_code AS '부서코드',
MAX(salary) AS '최고급여'
FROM employee
GROUP BY dept_code;
#1-2 각 부서별 최고 급여를 받는 직원들의 정보 조회
# 비효울적
SELECT emp_id AS '사번',
emp_name AS '사원명',
job_code AS '직급코드',
dept_code AS '부서코드',
salary AS '급여'
FROM employee
WHERE dept_code = 'D1' AND salary = 3660000
OR dept_code = 'D2' AND salary = 2490000
OR dept_code = 'D5' AND salary = 3760000
OR dept_code = 'D6' AND salary = 3900000
OR dept_code = 'D8' AND salary = 2550000
OR dept_code = 'D9' AND salary = 8000000
OR dept_code IS NULL AND salary = 2890000
;
#1-3 다중행, 다중열 서브쿼리를 사용하여 각 부서별 최고 급여를 받는 직원들의 정보 조회
SELECT emp_id AS '사번',
emp_name AS '사원명',
job_code AS '직급코드',
IFNULL(dept_code, '부서없음') AS '부서코드',
salary AS '급여'
FROM employee
WHERE ( IFNULL(dept_code, '부서없음'), salary) IN (
SELECT IFNULL(dept_code, '부서없음'),
MAX(salary)
FROM employee
GROUP BY dept_code
)
ORDER BY dept_code
;
#1-1#1-2#1-3
인라인 뷰 : FROM절에 서브 쿼리를 제시하고, 서브 쿼리를 수행한 결과를 테이블 대신에 사용
#1
SELECT emp_id AS '사번',
emp_name AS '사원명',
salary AS '급여',
salary * 12 AS '연봉'
FROM employee
;
SELECT e.사번,
e.사원명,
e.급여,
e.연봉
FROM (
SELECT emp_id AS '사번',
emp_name AS '사원명',
salary AS '급여',
salary * 12 AS '연봉'
FROM employee
)e;
#1 결과
-- employee 테이블에서 급여로 순위를 사원의 정보 출력
#2-1 employee 테이블에서 급여로 순위를 매겨서 출력
SELECT ROW_NUMBER() OVER (ORDER BY salary DESC) AS '순위',
emp_name AS '사원명',
salary AS '급여'
FROM employee
;
#2-2 서브쿼리(인라인 뷰)를 사용하여 급여 순위 5위인 사원의 정보 출력
SELECT e.순위,
e.사원명,
e.급여
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY salary DESC) AS '순위',
emp_name AS '사원명',
salary AS '급여'
FROM employee
)e
WHERE e.순위 = 5
;
#2-3 서브쿼리(인라인 뷰)를 사용하여 급여 순위 5위에서 10위인 사원의 정보 출력
SELECT e.순위,
e.사원명,
e.급여
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY salary DESC) AS '순위',
emp_name AS '사원명',
salary AS '급여'
FROM employee
)e
WHERE e.순위 BETWEEN 5 AND 10
;