Vim
1. Vim
- 윈도에 메모장 맥의 텍스트 편집기와 같은 편집기로 대부분의 리눅스 배포판에 기본으로 설치되어 있는 편집기
<vim 설치>
#1
$ vim --version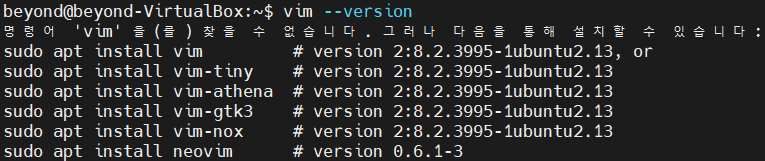
#2
# sudo : 관리자 권한
$ sudo apt update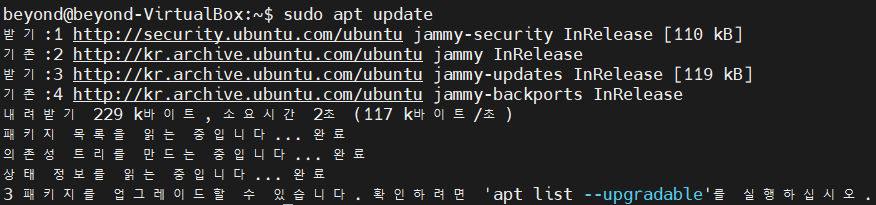
#3
$ sudo apt install vim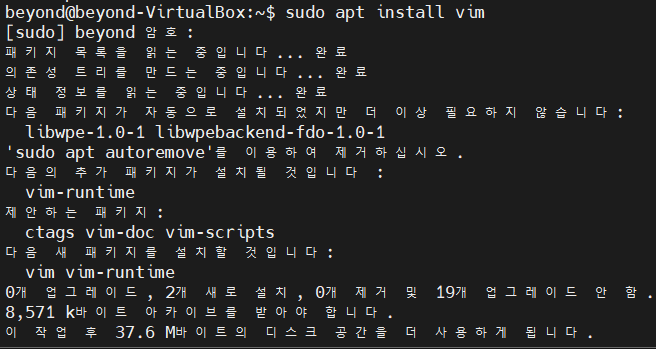
#4
$ vim --version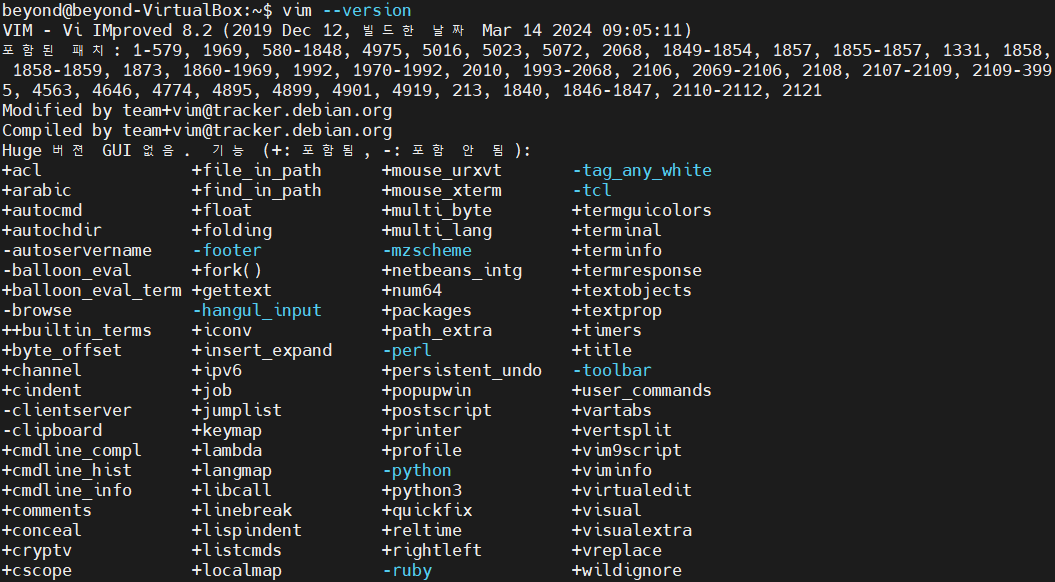
2. 실행과 종료
- Vim을 실행하려면 vim 명령어를 사용
vim <파일명>vim
- Vim을 실행할 때 파일 이름을 지정하면 해당 파일을 열 수 있음
- 이때 존재하지 않는 파일을 지정하면 해당 이름으로 파일을 새로 생성
- Vim을 종료하려면 Vim이 실행된 상태에서 :q를 입력하고 엔터
# 기존 파일 열기
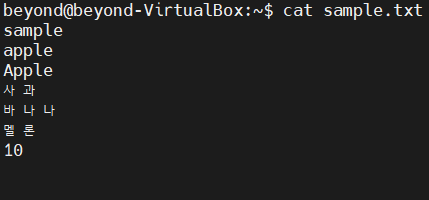
$ echo "sample" > sample.txt
# vim 명령어로 텍스트편집기에 sample.txt파일 열기
$ vim .sample.txt
# 새로운 파일 만들기 1
$ vim
$ :w[파일명]

# 새로운 파일 만들기 2
$ vim hello2.txt
# 파일 저장
$ :w
3. Vim의 모드
- Vim은 다른 에디터와 달리 모드(Mode)라는 것이 존재
- Vim은 명령어를 입력할 수 있는 보통 모드(Normal Mode)와 텍스트를 입력할 수 있는 입력 모드(Insert Mode)
- Vim을 실행하면 보통 모드에서 시작
- i, a, o를 누르면 입력 모드가 되고 입력 모드, esc를 누르면 보통 모드
# vim 모드 사용
$ vim hello1.txt
# 입력모드
i
# 내용을 입력하고 esc를 눌러 다시 보통모드로 전환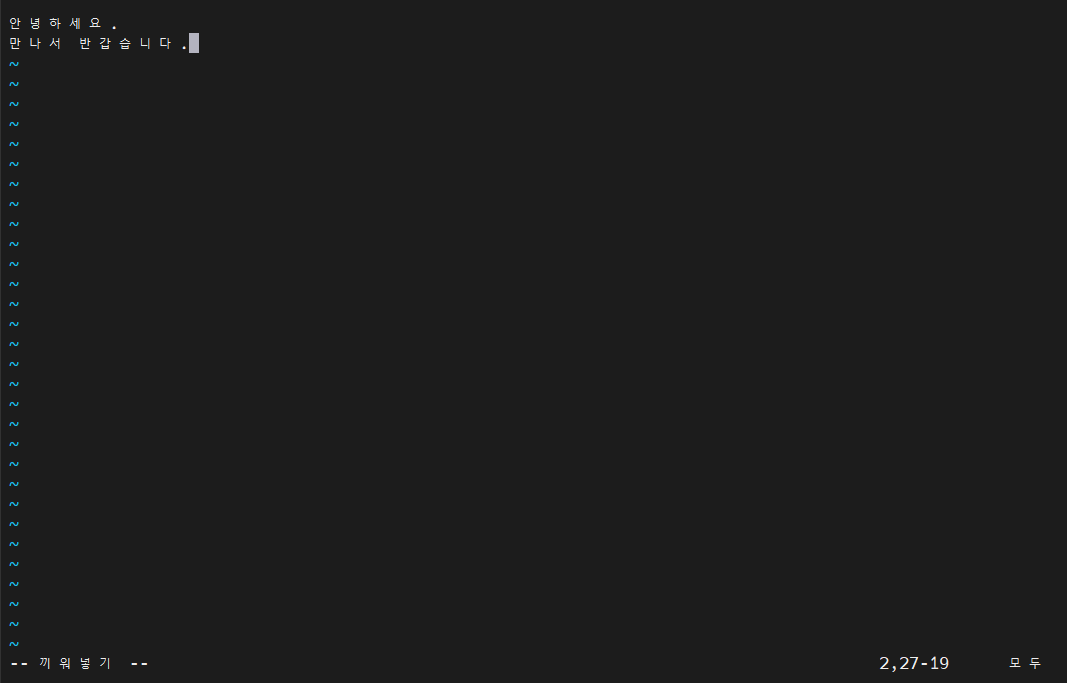
# 저장 후 종료
:wq# 파일 생성이 잘 되었는지 확인
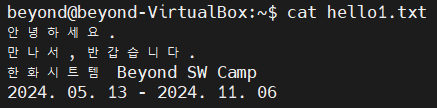
$ cat hello1
4. Vim 명령어
4.1. 파일 저장
- 편집 중인 파일을 저장하려면 보통 모드에서 :w 명령어를 사용
- 기존 파일을 열은 상태라면 덮어쓰게 되고, 새로운 파일 편집 중이라면 새로운 파일을 생성
4.2. 커서 이동
- 단어 단위로 커서를 이동하려면 보통 모드에서 w, b 명령어를 사용
- w는 다음 단어의 첫 글자로 이동
- b는 이전 단어의 첫 글자로 이동
- 공백을 기준으로 커서를 이동하고 싶을 때는 W, B 명령어를 사용한다.
- 행의 처음과 끝으로 커서를 이동하려면 보통 모드에서 0, $ 명령어를 사용
- 행 번호로 커서를 이동하려면 보통 모드에서 <행 번호>G 명령어를 사용
- 파일의 처음으로 커서를 이동하려면 gg, 파일의 마지막으로 커서를 이동하려면 G 명령어를 사용
# set number 명령어
# 보통 모드에서
:set number
4.3. 자르기(삭제), 복사, 붙여넣기
- 문자 하나를 자르려면 보통 모드에서 x 명령어를 사용
- 문자의 범위를 지정해서 자르려면 d 명령어로 범위를 지정해서 문자를 삭제 가능
- d$는 현재 커서 위치에서 행의 마지막까지 잘라냄
- d0는 현재 커서 위치에서 행의 시작까지 잘라냄
- dl은 문자 한 개를 잘라냄
- dw는 단어 한 개를 잘라냄
- dW : 공백 전까지 단어 한개를 잘라냄 - dgg는 현재 커서 위치의 행에서 문서 시작까지 잘라냄
- dG는 현재 커서 위치의 행에서 문서 끝까지 잘라냄
- 전체 행을 자르려면 보통 모드에서 dd 명령어를 사용한다.
4.4. 복사
- 문자의 범위를 지정해서 복사하려면 y 명령어로 범위를 지정해서 문자를 복사
- y$는 현재 커서 위치에서 행의 마지막까지 복사
- y0는 현재 커서 위치에서 행의 시작까지 복사
- yl은 문자 한 개를 복사
- yw는 단어 한 개를 복사
- ygg는 현재 커서 위치의 행에서 문서 시작까지 복사
- yG는 현재 커서 위치의 행에서 문서 끝까지 복사.
- 전체 행을 복사하려면 보통 모드에서 yy 명령어를 사용
4.5. 붙여넣기
- 삭제(자르기), 복사한 텍스트는 보통 모드에서 p 명령어로 원하는 곳에 붙여 넣을 수 있음
4.6. 취소와 재실행
- 보통 모드에서 u 명령어를 입력하면 방금 실행한 동작을 취소
- 취소한 동작에 대해 다시 실행하고 싶은 경우에는 보통 모드에서 Ctrl + r 명령어를 입력
4.7. 검색
- Vim은 파일에서 문자열을 검색할 수 있다.
- /문자열은 문자열을 아래 방향으로 검색
- ?문자열은 문자열을 위 방향으로 검색
- n은 검색 결과가 여러 개라면 다음 검색 결과로 이동
- N은 검색 결과가 여러 개라면 이전 검색 결과로 이동
텍스트 처리
- 리눅스에서는 애플리케이션의 데이터나 시스템의 설정 항목이 대부분 텍스트로 되어 있다.
- 따라서 리눅스에는 텍스트를 효과적으로 다루는 명령어가 다수 존재한다.
2. 바이트 수, 단어 수, 행의 수 세기
- 바이트 수, 단어 수, 행의 수를 출력하려면 wc 명령어를 사용
# 행의 수, 단어 수, 바이트 수를 출력
$ wc <파일 이름>

# 행의 수만 출력
$ wc -l <파일 이름>
# 단어 수만 출력
$ wc -w <파일 이름>
# 바이트 수만 출력
$ wc -c <파일 이름>
3. 행 단위로 정렬
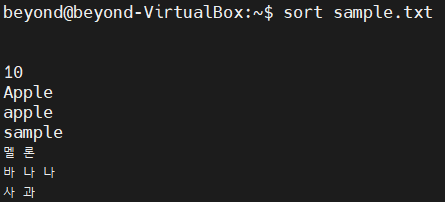
- 행 단위로 정렬하여 출력하려면 sort 명령어를 사용
# 공백 > 숫자 > 영어(글자수 적은 것 부터 |대문자 > 소문자 | 알파벳 순)
# > 한글(글자수 적은것부터 | 가나다순)
$ sort [파일명]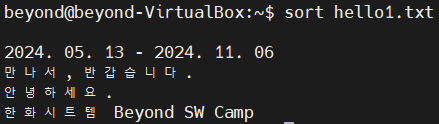
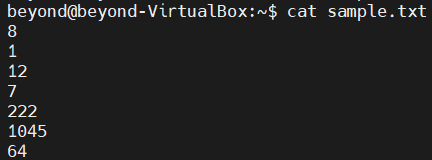
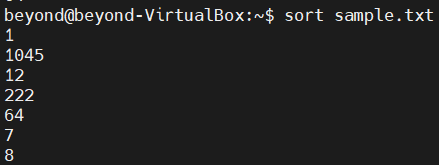
# 문자열을 code값으로 저장하기 때문에 숫자로 정렬하는 것이 아닌 code값으로 비교
# 숫자의 첫번째 자리의 code값으로 정렬한 후 다음번째 자리의 code값으로 정렬을 반복
# 숫자 값으로 정렬
$ sort -n <파일 이름>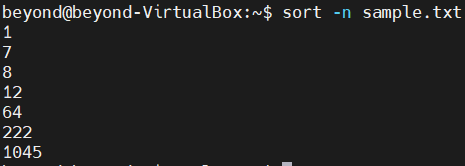
# 역순으로 정렬
$ sort -r <파일 이름>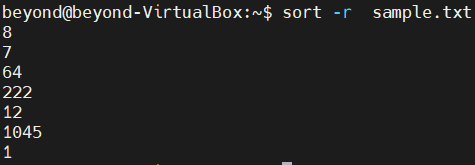
# 숫자 값이 큰 순으로 정렬
$ sort -nr <파일 이름>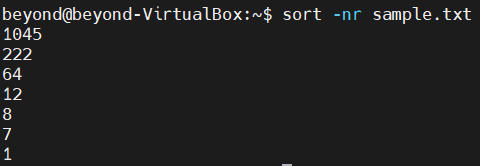
#명령어 여러개 한번에 사용하기 ( | : 파이프라인 기호)
# |는 앞에 있는 연산의 결과를 다음에 있는 다음 명령어에게 전달(표준 입력으로 전달)
# -k는 field를 나타내는 옵션
# 5는 5번째 filed를 의미
ls -l | sort -k 5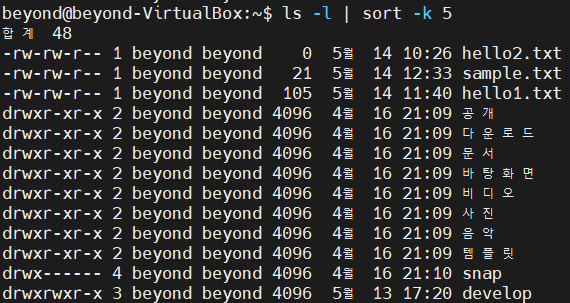
- 연속된 중복 데이터를 하나만 출력하려면 uniq 명령어를 사용
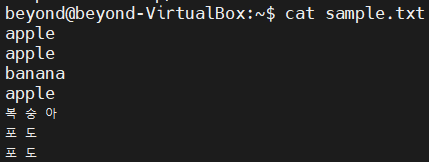
# 중복된 데이터를 제거
# 연속된 문자열에 한에서만 중복을 제거
$ uniq <파일 이름>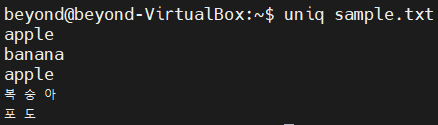
# sample.txt 정렬 후에 uniq 연산 실행
$ sort sample.txt | uniq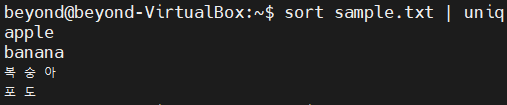
# sort 옵션 -u와 sort sample.txt|uniq 결과 동일
$sort -u sample.txt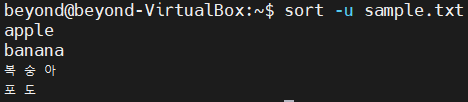
# 중복된 행의 개수 출력
$ uniq -c <파일 이름>
- 입력의 일부를 추출하여 출력하려면 cut 명령어를 사용
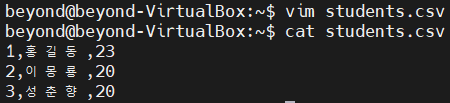
> .csv 파일 : 몇가지 필드를 콤마(,)로 구분한 텍스트 데이터 및 텍스트 파일
cut -d, -f 2 studnets.csv
#passwd 파일은 계정의 정보를 가지고 있음
cat /etc/passwd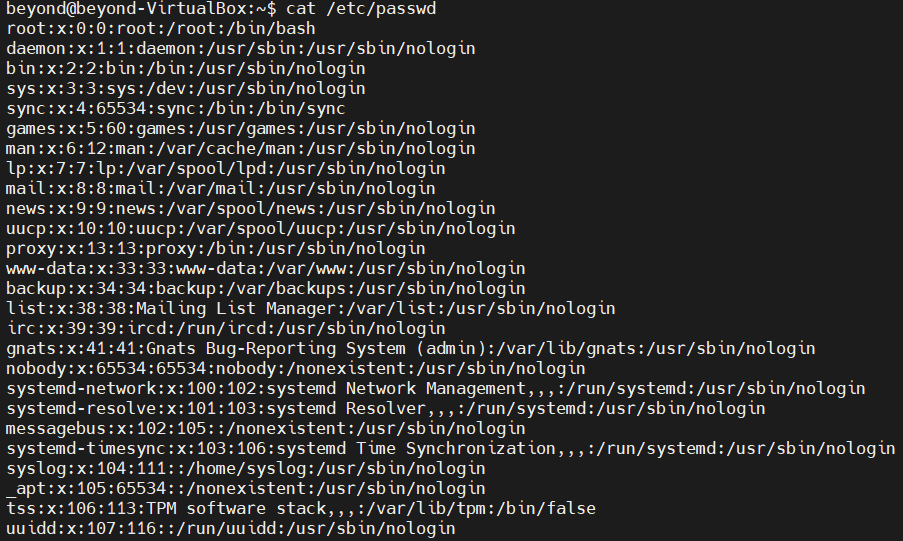
cut -d : -f 1/ etc/passwd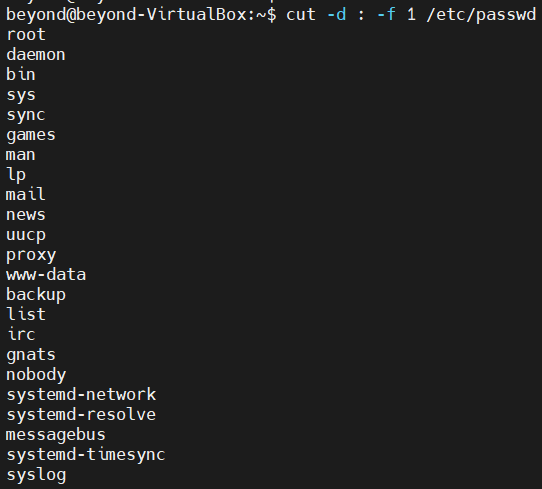
cut -d : -f 1.7 /etc/passwd
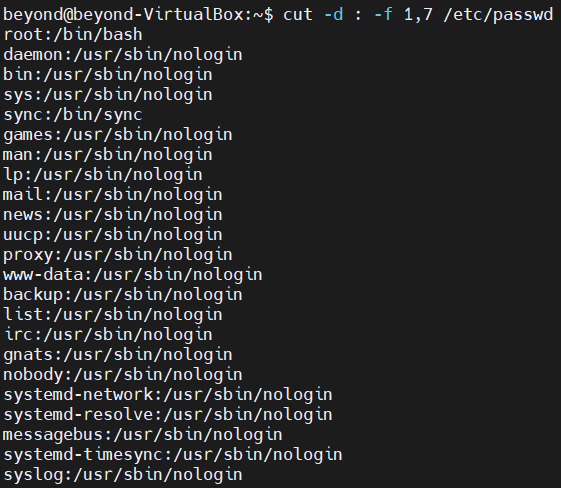
cut -d : -f 1,7 etc/passwd | grep '/bin/bash'
6. 문자 치환
- 문자를 치환하려면 tr 명령어를 사용
# tr은 표준 입력으로만 입력값을 받음
$ tr <치환 전 문자> <치환 후 문자>
# passwd의 :(콜론) 기호를 ,(콤마)로 바꾸는 작업
#방법 1
cat /etc/passwd | tr : ,
#방법2
# 파일을 직접 지정한 것이 아님
tr : , < /etc/passwd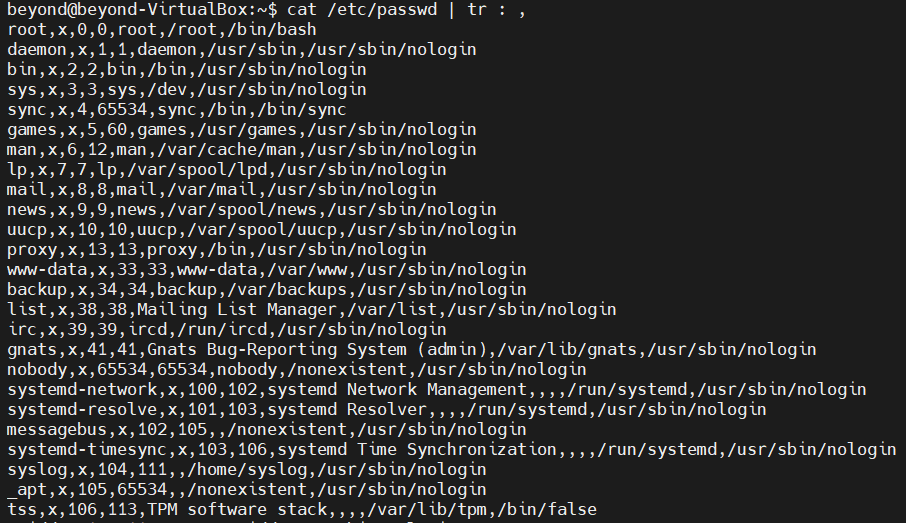
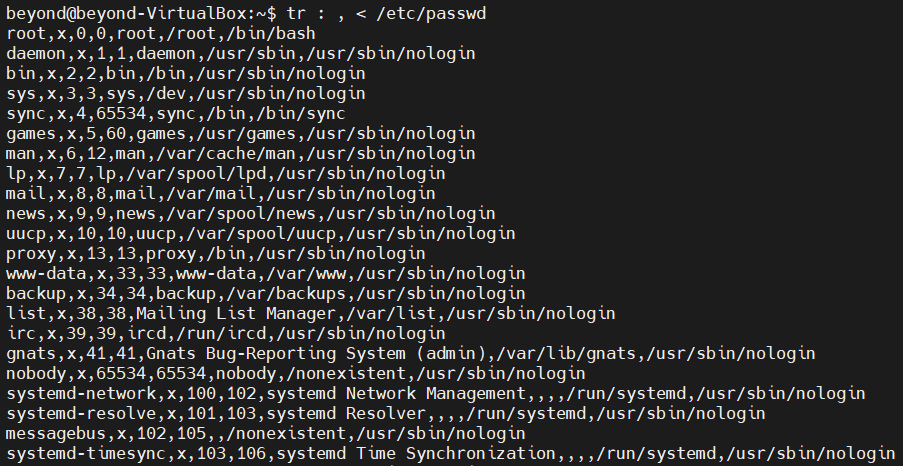
명령어에 따라 출력하는 값을 콘솔에 출력는데 이것을 표준출력이라고 함
> 기호 : 표준 출력을 변경해줌 (표준 출력 리다이렉션)
# >>기호는 중복했을때 덮어쓸 것인지 진행여부 확인
ls > ls.txt
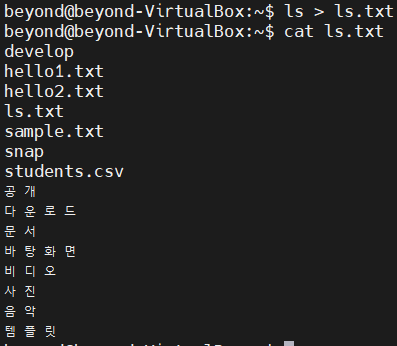
에러출력을 리다이렉션할때는 2> 기호를 사용
ls /aaa 2> error.txt
<기호 : 표준입력을 변경해줌(표준 입력 리다이렉션)
# 표준출력인 키보드로부터가 아닌 students.csv파일을 입력으로 받도록 리다이렉션
cat students.csv
# passwd의 소문자를 모두 대문자로 변경하는 작업
# | 명령어는 실행결과를 다음 명령어에게 표준 입력으로 전달해줌
cat /etc/passwd | tr a-z A-Z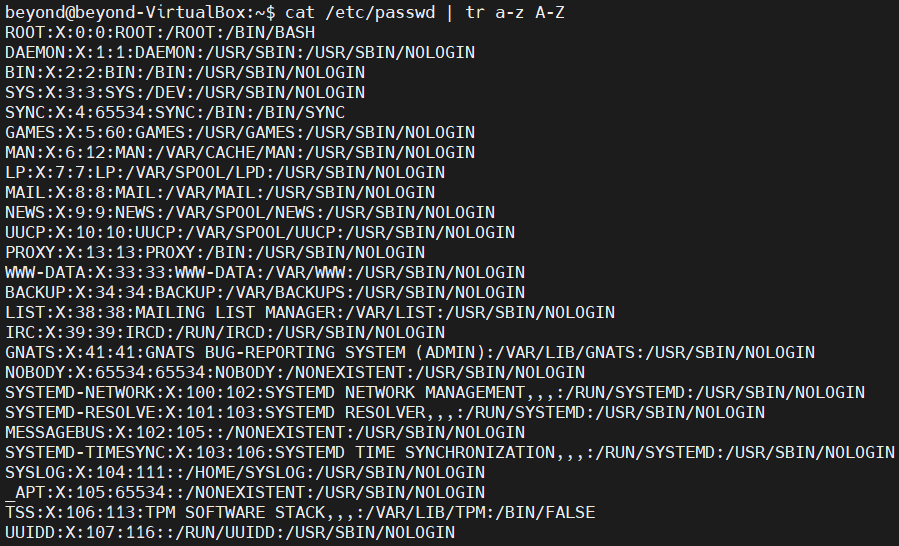
7. 파일의 마지막 부분 출력
- 파일의 마지막 내용부터 출력하려면 tail 명령어를 사용
# 파일의 마지막 10개 행을 출력
tail <파일 이름>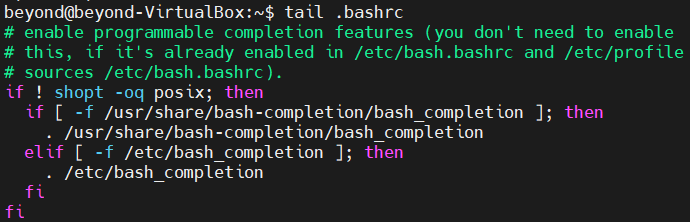
# 파일의 마지막 5개 행을 출력
tail -n 5 <파일 이름>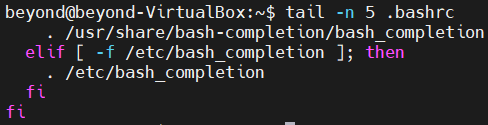
- tail 명령어에 -f 옵션을 사용하면 파일의 내용이 추가될 때마다 실시간으로 내용을 출력하여 파일을 모니터링할 수 있음
# 종료시 ctrl+c
tail -f <파일 이름>$ tail -f sample.txt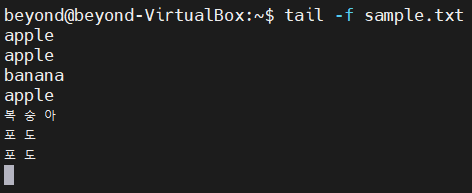
# tail -f sample.txt 실행중
# 다른 세션에서 sample.txt에 "오렌지" 텍스트 추가
ehco "오렌지" >> sample.txt
# 처음부터 계속 실행중
# 모니터링을 계속하다가 다른 세션에서 "오렌지" 데이터 추가시
# "오렌지" 출력
$ tail -f sample.txt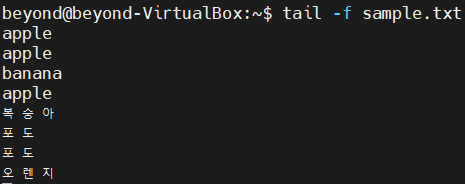
- tail의 반대로 동작하는 명령어는 head 명령어
# 파일의 처음 10개 행을 출력
head <파일 이름>$ head .bashrc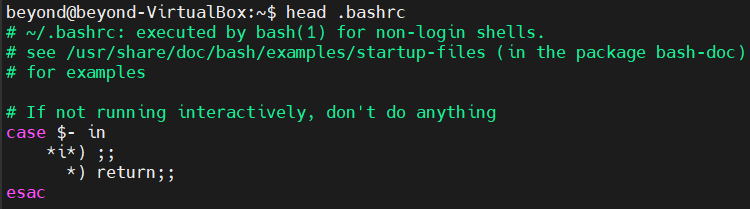
# 파일의 처음 5개 행을 출력
head -n 5 <파일 이름>
'Linux' 카테고리의 다른 글
| [Linux] 계정 관리 / 파일 접근 권한 (0) | 2024.05.18 |
|---|---|
| [Linux] 파일/디렉터리 조작 (0) | 2024.05.17 |
| [Linux] 파일/디렉터리 (0) | 2024.05.17 |
| [Linux] 리눅스(Linux)/ 셸(Shell) (0) | 2024.05.17 |
| [Linux] ssh 인증키 설정 (0) | 2024.05.14 |